Telefonunuz masanın üzerinde dururken bile GPS noktası birkaç metre oraya buraya zıplar. Arabadaki ivmeölçer mükemmel veri verir ama integralini aldığınızda hata saniyeler içinde birikip sürüklenir (drift). Tek başına ne sensöre ne de modele güvenebilirsiniz — yine de haritadaki maviniz pürüzsüz, kararlı bir çizgi çizer. Bu sihrin arkasındaki makine çoğu zaman aynıdır: Kalman filtresi.
Kalman filtresi, 1960’ta Rudolf Kálmán’ın ortaya koyduğundan beri uzay araçlarından telefonunuza, robotlardan finansal modellere kadar her yerde çalışan, gürültülü ölçümler ile kusurlu bir hareket modelini optimal şekilde harmanlayan özyinelemeli bir kestirimcidir. Bu yazıda filtreyi sıfırdan kuracağız: önce Gauss dağılımlarını birleştirme sezgisiyle, sonra doğrusal durum-uzay modeliyle, ardından doğrusal-olmayan dünyaya geçişi sağlayan Genişletilmiş Kalman Filtresi (EKF) ile. Yol boyunca hem NumPy ile tam çalışan Python kodları hem de tarayıcınızda canlı oynayabileceğiniz iki etkileşimli simülatör olacak.
Problem: Gizli Durumu Gürültünün Altından Çıkarmak
Bir sistemin gerçekten bilmek istediğimiz büyüklüklerine durum (state) diyelim ve x ile gösterelim — bir cismin konumu ve hızı, bir uydunun yörünge parametreleri, bir bataryanın şarj seviyesi. Sorun şu ki durumu doğrudan göremeyiz. Elimizde sadece iki kusurlu bilgi kaynağı vardır:
- Bir hareket modeli. Fizik bize “bir sonraki adımda durum kabaca şu olur” der. Ama model idealdir; rüzgâr, sürtünme, modellenmemiş ivmeler yüzünden gerçekten sapar ve bu sapma adım adım birikir.
-
Gürültülü ölçümler. Sensör bize durumla ilgili bir şey söyler (
z), ama her okumanın üzerinde rastgele gürültü vardır. Üstelik sensör çoğu zaman durumun tamamını değil, bir fonksiyonunu ölçer (örneğin yalnızca konumu, hızı değil).
Kalman filtresinin yaptığı tam olarak şudur: her adımda modelin tahminiyle yeni ölçümü, her birinin ne kadar güvenilir olduğunu hesaba katarak birleştirir. Kritik nokta, filtrenin yalnızca en iyi tahmini (x̂) değil, o tahmine ne kadar güvendiğini de (kovaryans matrisi P) taşımasıdır. Tüm zekâ bu ikinci büyüklükte saklıdır.
Bir de güzel özelliği var: filtre özyinelemelidir (recursive). Tüm geçmiş ölçümleri saklamaz; her an yalnızca güncel x̂ ve P değerlerini tutar, yeni ölçüm gelince bunları günceller. Bu yüzden gömülü bir mikrodenetleyicide, sabit hafızayla, gerçek zamanlı çalışabilir.
Gauss Dağılımı ve İki Bilgiyi Birleştirmek
Kalman filtresinin kalbinde tek bir varsayım yatar: belirsizliği Gauss (normal) dağılımıyla temsil ederiz. Bir Gauss iki sayıyla tanımlanır: ortalama μ (“en iyi tahminim”) ve varyans σ² (“ne kadar eminim” — küçük varyans = sivri, emin; büyük varyans = yayvan, belirsiz).
Şimdi sihirli kısım. Elimizde aynı büyüklük hakkında iki bağımsız Gauss bilgi olsun: biri modelin tahmini, diğeri ölçüm. Bu ikisini çarptığımızda ortaya çıkan şey yine bir Gauss’tur — ve bu yeni Gauss, her ikisinden de daha dardır, ortalaması da ikisinin “kesinliklerine göre ağırlıklı” ortasındadır:
$$ \mu = \mu_1 + \frac{\sigma_1^2}{\sigma_1^2 + \sigma_2^2}\,(\mu_2 - \mu_1), \qquad \sigma^2 = \sigma_1^2 - \frac{\sigma_1^4}{\sigma_1^2 + \sigma_2^2} $$
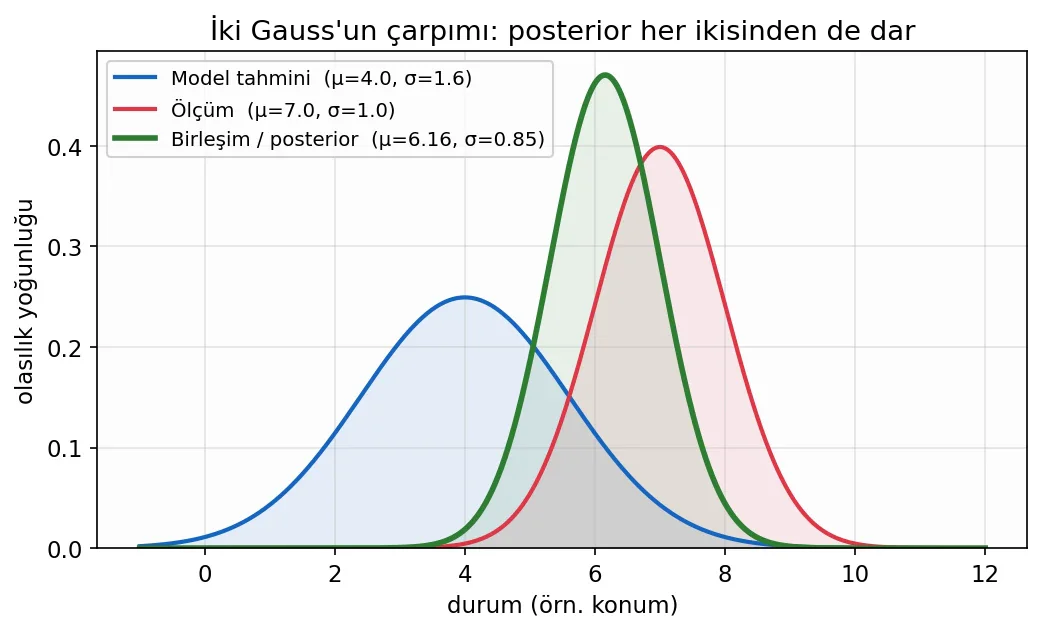
İki şeye dikkat edin. Birincisi, ortalamanın kaydığı miktar σ₁²/(σ₁²+σ₂²) ağırlığıyla belirlenir — bu ifade tam olarak skaler Kalman kazancıdır (K). İkincisi, sonuçtaki varyans her iki girdiden de küçüktür: iki bağımsız bilgiyi birleştirmek belirsizliği azaltır, asla artırmaz. Güncelleme denklemini şöyle de yazabiliriz:
$$ \mu = \mu_1 + K\,(\mu_2 - \mu_1), \qquad K = \frac{\sigma_1^2}{\sigma_1^2 + \sigma_2^2} $$
Bu, birazdan göreceğimiz tam Kalman güncellemesinin (x̂ = x̂⁻ + K(z − x̂⁻)) bire bir skaler hâlidir. Geriye kalan tek iş, bunu tek boyuttan matrislere taşımak.
Doğrusal Durum-Uzay Modeli
Çok boyutlu durumda μ yerine durum vektörü x, σ² yerine kovaryans matrisi P geçer. Sistemi şu iki denklemle modelleriz:
$$ x_k = F\,x_{k-1} + B\,u_{k-1} + w_{k-1}, \qquad w_{k-1} \sim \mathcal{N}(0, Q) $$
$$ z_k = H\,x_k + v_k, \qquad v_k \sim \mathcal{N}(0, R) $$
Terimleri tek tek tanıyalım:
-
F— durum geçiş matrisi: bir adımda durumun fizikçe nasıl evrildiği. -
B,u— kontrol matrisi ve kontrol girdisi: dışarıdan uyguladığımız, bildiğimiz etkiler (örneğin gaz/fren). Kontrol yoksa bu terim düşer. -
H— ölçüm matrisi: durumun hangi bileşeninin, nasıl ölçüldüğü. -
Q— süreç gürültüsü kovaryansı: modele ne kadar güvenmediğimiz. BüyükQ= “modelim kaba, gerçek bundan sapabilir”. -
R— ölçüm gürültüsü kovaryansı: sensöre ne kadar güvenmediğimiz. Genelde sensörün datasheet’inden ya da kalibrasyondan bilinir. -
P— kestirim kovaryansı: filtrenin o anki tahminine olan güveni. Filtre bunu kendisi üretir ve günceller.
Somut bir örnek kuralım: bir doğru üzerinde, yaklaşık sabit hızla giden bir cisim. Durumu konum ve hızdan oluşsun, Δt adım süresi olsun. Yalnızca konumu ölçebildiğimizi varsayalım. O zaman:
$$ x_k = \begin{bmatrix} p_k \\ \dot{p}_k \end{bmatrix}, \quad F = \begin{bmatrix} 1 & \Delta t \\ 0 & 1 \end{bmatrix}, \quad H = \begin{bmatrix} 1 & 0 \end{bmatrix} $$
F‘in anlamı net: yeni konum = eski konum + hız·Δt; yeni hız = eski hız (sabit hız varsayımı). H = [1, 0] ise “ölçüm sadece konumu görür, hızı görmez” der. Hızı hiç ölçmediğimiz hâlde filtre onu konum ölçümlerinin zaman içindeki değişiminden çıkarsayacak — Kalman filtresinin en şık tarafı budur.
Süreç gürültüsünü, modellenmemiş bir ivmeden gelir gibi düşünürüz (beyaz-gürültü ivme modeli):
$$ Q = q\begin{bmatrix} \tfrac{\Delta t^4}{4} & \tfrac{\Delta t^3}{2} \[4pt] \tfrac{\Delta t^3}{2} & \Delta t^2 \end{bmatrix}, \qquad R = \begin{bmatrix} \sigma_{\text{ölç}}^2 \end{bmatrix} $$
Buradaki q skaler bir “süreç gürültüsü yoğunluğu”dur ve birazdan en kritik ayar düğmemiz olacak.
Tahmin Adımı (Predict)
Filtre iki adımlı bir danstır. İlk adım tahmin: mevcut durumu ve belirsizliği, modeli kullanarak bir adım ileri taşırız.
$$ \hat{x}_k^- = F\,\hat{x}_{k-1} + B\,u_{k-1} $$
$$ P_k^- = F\,P_{k-1}\,F^{\mathsf{T}} + Q $$
Üstteki − işareti “henüz ölçümü görmeden, sadece modele dayalı a-priori tahmin” demektir. Birinci denklem sezgisel: durumu fizik kurallarıyla ileri sür. İkinci denklem daha derin: belirsizliği de ileri taşırız, ama F P Fᵀ ile dönüştürüp üzerine + Q ekleriz. Bu + Q çok önemli — tahmin adımı belirsizliği daima büyütür. Mantıklı: modele güvenerek geleceğe baktıkça emin olduğumuz şey azalır. Konum-hız örneğinde belirsizlik elipsi, hız yönünde uzar; çünkü hızdaki ufak bir hata, zamanla konumda büyük bir belirsizliğe dönüşür.
Güncelleme Adımı (Update)
İkinci adım güncelleme: yeni ölçüm gelince tahmini düzeltiriz. Burası Gauss çarpımının matris hâlidir.
$$ y_k = z_k - H\,\hat{x}_k^- $$
$$ S_k = H\,P_k^-\,H^{\mathsf{T}} + R $$
$$ K_k = P_k^-\,H^{\mathsf{T}}\,S_k^{-1} $$
$$ \hat{x}_k = \hat{x}_k^- + K_k\,y_k $$
$$ P_k = (I - K_k H)\,P_k^- $$
Sırayla:
-
y— yenilik (innovation): ölçüm bizi ne kadar şaşırttı? Beklediğimiz ölçüm (H x̂⁻) ile gerçek ölçüm (z) arasındaki fark. Yenilik küçükse model isabetli, büyükse ölçümde yeni bilgi var. -
S— yeniliğin kovaryansı: bu şaşkınlığın ne kadarı beklenen (gürültü + model belirsizliği). -
K— Kalman kazancı: filtrenin kalbi. Yeniliğin ne kadarına güveneceğimizi belirleyen, hassasiyete göre ağırlıklı harman oranı.K → 1ise “sensöre güven, ölçümü kabul et”;K → 0ise “modele güven, ölçümü neredeyse yok say”. - Durum güncellemesi: a-priori tahmine, yeniliğin
Kkatını ekle. - Kovaryans güncellemesi: tahmin belirsizliği azalır (yeni bilgi geldi).
Pratikte son denklem yerine sayısal olarak daha kararlı olan Joseph formu tercih edilir; her durumda simetrik ve pozitif yarı-tanımlı bir P üretir:
$$ P_k = (I - K_k H)\,P_k^-\,(I - K_k H)^{\mathsf{T}} + K_k R\,K_k^{\mathsf{T}} $$
Buna birazdan “Mühendislik Notları”nda döneceğiz.
Tam Algoritma: İki Adımın Dansı
Tüm filtre, bu iki adımın sonsuza dek tekrarından ibarettir:
x₀ , P₀ (büyük)"] --> PRED subgraph TAHMIN["① TAHMİN (Predict)"] PRED["x⁻ = F·x + B·u
P⁻ = F·P·Fᵀ + Q
(belirsizlik artar)"] end subgraph GUNC["② GÜNCELLEME (Update)"] UPD["y = z − H·x⁻
K = P⁻·Hᵀ·S⁻¹
x = x⁻ + K·y
P = (I − K·H)·P⁻
(belirsizlik azalır)"] end PRED -->|a priori tahmin| UPD Z(["ölçüm z"]) --> UPD UPD -->|a posteriori kestirim| PRED UPD --> OUT["çıktı: x , P"] style INIT fill:#e8eef7,stroke:#4a6fa5,stroke-width:2px style PRED fill:#cee0f3,stroke:#3a5f95,stroke-width:2px style UPD fill:#bfd6f0,stroke:#3a5f95,stroke-width:2px style Z fill:#fde0e0,stroke:#c0392b,stroke-width:2px style OUT fill:#d5f0d5,stroke:#2e7d32,stroke-width:2px
Başlangıçta x̂₀ için bir tahmin (bilmiyorsak sıfır) ve P₀ için büyük bir değer veririz — “başta hiçbir şey bilmiyorum” demenin yolu budur. İlk birkaç ölçümde filtre hızla kendine gelir; kötü bir başlangıcı çabucak unutur. Bu, Kalman filtresinin pratikteki en sevimli huylarından biridir.
Elde Çalışan 1B Örnek
Soyut kalmasın; ilk iterasyonu elle yapalım. Konum-hız modelimizde Δt = 1, σ_ölç = 2 (yani R = 4), q = 0.01 olsun. Başlangıç: x̂₀ = [0, 0], P₀ = 500·I (çok belirsiz).
Tahmin: x̂⁻ = F·[0,0]ᵀ = [0, 0]. Kovaryans için P⁻ = F P₀ Fᵀ + Q. Hesabı yapınca P⁻[0,0] ≈ 1000 çıkar (belirsizlik tahminle daha da büyüdü).
İlk ölçüm geldi: diyelim z₁ = 2.64. O zaman:
- Yenilik:
y = z₁ − x̂⁻[0] = 2.64 − 0 = 2.64 - Yenilik kovaryansı:
S = P⁻[0,0] + R = 1000 + 4 = 1004 - Kalman kazancı:
K = [P⁻[0,0], P⁻[0,1]]ᵀ / S = [0.996, 0.498]ᵀ - Durum:
x̂ = x̂⁻ + K·y = [0.996·2.64, 0.498·2.64] = [2.63, 1.31] - Kovaryans:
P[0,0] = (1 − 0.996)·1000 ≈ 4.0
İlk adımda K ≈ 1 çıkması tesadüf değil: P₀ kocaman olduğu için filtre “modelime hiç güvenmiyorum, ölçüm neredeyse aynen doğrudur” diyor ve ilk ölçümü olduğu gibi kabul ediyor. Konum varyansı 1000’den 4’e düştü; bir ölçümle ne kadar çok şey öğrendiğimize bakın. Adımlar ilerledikçe K küçülerek kararlı bir değere oturacak — filtre artık modeline de güvenmeye başlayacak.
NumPy ile Sıfırdan Lineer KF
Teori güzel ama her zaman dediğim gibi, gözünüzle görmediğiniz hiçbir şeye güvenmeyin. Aşağıdaki kod modeli kurar, gerçek bir yörünge ile gürültülü ölçümler üretir ve filtreyi çalıştırır. Toplam 20 satırlık bir döngü.
import numpy as np
import matplotlib.pyplot as plt
dt = 1.0
F = np.array([[1, dt],
[0, 1.0]]) # sabit-hız geçiş matrisi
H = np.array([[1.0, 0.0]]) # yalnızca konumu ölçüyoruz
q = 0.01 # süreç gürültüsü yoğunluğu
Q = q * np.array([[dt**4/4, dt**3/2],
[dt**3/2, dt**2]])
R = np.array([[4.0]]) # ölçüm gürültüsü (σ=2 → R=σ²=4)
# 1) Gerçek yörünge + gürültülü ölçümler üret
rng = np.random.default_rng(1)
N = 60
x = np.array([0.0, 1.0]) # [konum, hız]
truth, meas = [], []
for _ in range(N):
x = F @ x + np.array([0.0, rng.normal(0, np.sqrt(q))])
truth.append(x.copy())
meas.append((H @ x)[0] + rng.normal(0, 2.0))
truth, meas = np.array(truth), np.array(meas)
# 2) Kalman filtresini çalıştır
xhat = np.array([0.0, 0.0])
P = np.eye(2) * 500.0 # başlangıçta çok belirsiziz
I = np.eye(2)
est, var_p, gain = [], [], []
for k in range(N):
# --- TAHMİN ---
xhat = F @ xhat
P = F @ P @ F.T + Q
# --- GÜNCELLEME ---
y = meas[k] - H @ xhat # yenilik
S = H @ P @ H.T + R
K = P @ H.T @ np.linalg.inv(S) # Kalman kazancı
xhat = xhat + (K @ y)
P = (I - K @ H) @ P
est.append(xhat.copy()); var_p.append(P[0, 0]); gain.append(K[0, 0])
est = np.array(est)
rmse_kf = np.sqrt(np.mean((est[:, 0] - truth[:, 0])**2))
rmse_raw = np.sqrt(np.mean((meas - truth[:, 0])**2))
print(f"KF RMSE={rmse_kf:.2f} ham ölçüm RMSE={rmse_raw:.2f}")
# -> KF RMSE=0.73 ham ölçüm RMSE=1.64
Sonuç çarpıcı: ham ölçümlerin gerçek konuma göre RMSE’si 1.64 iken, Kalman kestiriminin RMSE’si 0.73 — kabaca 2.25 kat daha iyi. Hem de tek bir ekstra sensör eklemeden, yalnızca bir hareket modelini akıllıca kullanarak.
Bir de filtrenin “kendine güveni” olan P ve kazanç K‘nin zaman içindeki davranışına bakalım:
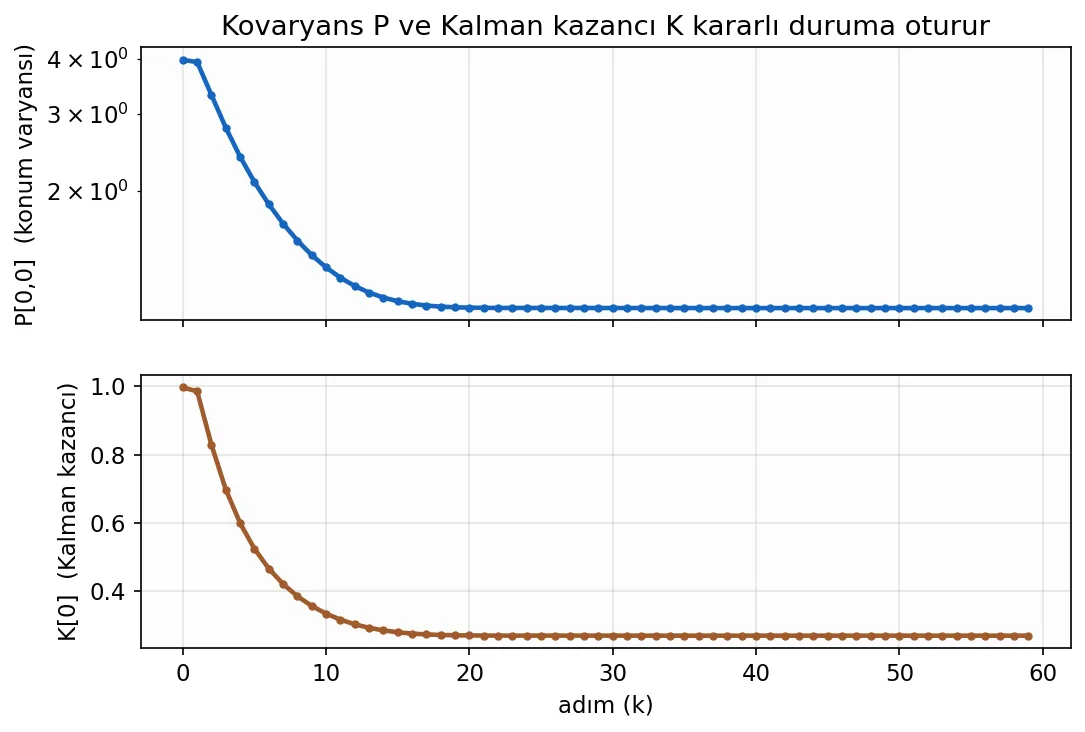
R ve q değerleriyle oynayıp kodu yeniden çalıştırın: R‘yi büyütürseniz filtre ölçümlere daha az güvenir, kestirim pürüzsüzleşir ama yavaşlar. q‘yu büyütürseniz modele daha az güvenir, kestirim ölçümlerin peşinden koşar. Bu dengeyi en iyi, doğrudan elinizle hissederek anlarsınız — buyrun.
Etkileşimli Simülatör: Lineer Kalman Filtresi
Aşağıdaki simülatör gerçek zamanlı çalışır. Üç düğme var: ölçüm gürültüsü σ, filtrenin varsaydığı süreç gürültüsü q ve cismin gerçek hızı. Gerçek dünya sabit (ama hafif manevra yapan) bir hızla ilerler; siz filtreyi nasıl ayarladığınıza göre sonucu izleyin.
σ'yı büyüt → kestirim pürüzsüzleşir ama gecikir. q'yu büyüt → kestirim her ölçümün peşinden koşar. q'yu çok küçültürsen filtre fazla kendine güvenir: ±2σ bandı incelir ama gerçek konum bandın dışına taşar (ıraksamanın habercisi).
Birkaç deney önerisi: q‘yu en küçük değere çekin ve birkaç saniye izleyin — güven bandı kâğıt inceliğine düşerken gerçek (yeşil) çizginin bandın dışına kaçtığını göreceksiniz. Filtre kendine olduğundan fazla güveniyor; bu, gerçek sistemlerde ıraksamanın (divergence) klasik reçetesidir. Sonra q‘yu sonuna kadar açın: bu sefer kestirim her gürültülü noktanın peşine takılır, filtrenin tüm pürüzsüzleştirme faydası kaybolur. İyi ayar ikisinin arasındadır.
Doğrusal Olmama Problemi: Sensör Düz Konuşmaz
Şimdiye kadar her şey doğrusaldı: x = F x ve z = H x. Gerçek dünyaysa nadiren bu kadar kibardır. Çoğu sensör, durumun doğrusal-olmayan bir fonksiyonunu ölçer.
Klasik örnek: orijine yerleştirilmiş bir sensör, hareketli bir cisme olan uzaklığı (menzil, r) ve açıyı (θ) ölçsün. Cismin konumu Kartezyen (p_x, p_y) ise, ölçüm şudur:
$$ h(x) = \begin{bmatrix} r \\ \theta \end{bmatrix} = \begin{bmatrix} \sqrt{p_x^2 + p_y^2} \[4pt] \operatorname{atan2}(p_y, p_x) \end{bmatrix} $$
İçindeki karekök ve atan2 yüzünden bu fonksiyon durumda doğrusal değildir. İşte sorun: Kalman filtresinin tüm matematiği “Gauss içeri girer, Gauss dışarı çıkar” varsayımına dayanır. Ama bir Gauss dağılımını doğrusal-olmayan bir fonksiyondan geçirirseniz, çıkan şey artık Gauss değildir — çarpık, eğri büğrü bir dağılımdır. H matrisi diye bir şey de yoktur; h(x) bir matrisle yazılamaz. Klasik KF burada çalışmaz.
(Aynı sorun ölçümde değil süreçte de olabilir: x = f(x, u) doğrusal-olmayan bir hareket modeli olabilir — dönen bir cisim, sürtünmeli bir sarkaç. Çözüm her iki durumda da aynıdır.)
EKF’in Fikri: Lineerizasyon ve Jacobian’lar
Genişletilmiş Kalman Filtresi’nin (EKF) çözümü zarif ve pragmatiktir: doğrusal-olmayan fonksiyonu, içinde bulunduğumuz çalışma noktasının yakınında bir doğruyla (teğetle) değiştir. Yani her adımda, güncel tahmin x̂ etrafında birinci-dereceden Taylor açılımı yaparız. Bu teğetin eğimi, fonksiyonun Jacobian matrisidir:
$$ F_k = \left.\frac{\partial f}{\partial x}\right|_{\hat{x}_{k-1},\,u_{k-1}}, \qquad H_k = \left.\frac{\partial h}{\partial x}\right|_{\hat{x}_k^-} $$
Fikir basit ama güçlü: kovaryansı taşırken ve Kalman kazancını hesaplarken, sabit F ve H matrislerinin yerine bu her adımda yeniden hesaplanan Jacobian’ları kullanırız. Durumun kendisini taşırken ise gerçek doğrusal-olmayan f ve h fonksiyonlarını kullanmaya devam ederiz (teğeti değil, eğrinin kendisini).
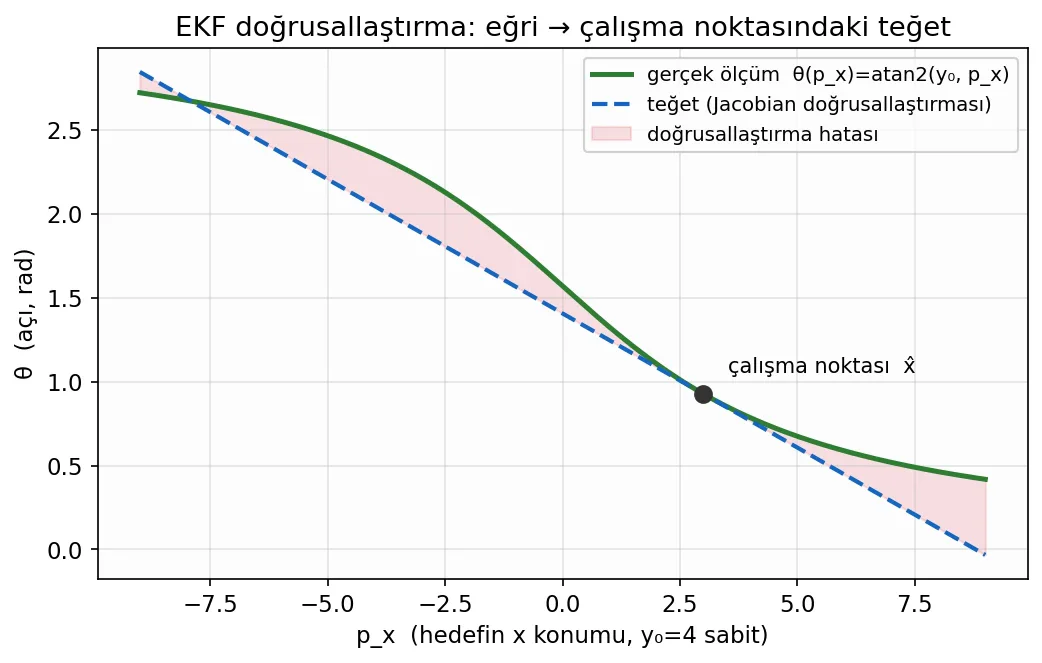
Bu yaklaşımın bedeli de aynı resimde: EKF artık optimal değildir ve doğrusallık varsayımı yalnızca çalışma noktasının yakınında geçerlidir. Tahmin gerçekten uzaksa veya fonksiyon çok bükülmüşse, teğet kötü bir yaklaşım olur ve filtre ıraksayabilir. Yine de pratikte EKF, on yıllardır navigasyon ve takip sistemlerinin bel kemiğidir; çünkü çoğu sistem, adım adım bakıldığında “yeterince doğrusal”dır.
Range-Bearing Jacobian’ını Elle Türetmek
EKF’i uygulamak demek, Jacobian’ı doğru türetmek demektir; gerisi neredeyse klasik KF’tir. Menzil-açı ölçümümüz için H_k = ∂h/∂x türevini eleman eleman alalım. Durumumuz [p_x, p_y, v_x, v_y] ve r = √(p_x² + p_y²).
Menzil satırı için:
-
∂r/∂p_x = p_x / r,∂r/∂p_y = p_y / r
Açı satırı için (θ = atan2(p_y, p_x) türevinin standart sonucu):
-
∂θ/∂p_x = −p_y / r²,∂θ/∂p_y = p_x / r²
Hız bileşenlerine göre türevler sıfırdır, çünkü ölçüm hıza doğrudan bağlı değil. Hepsini bir matriste toplayınca:
$$ H_k = \frac{\partial h}{\partial x} = \begin{bmatrix} \dfrac{p_x}{r} & \dfrac{p_y}{r} & 0 & 0 \[8pt] -\dfrac{p_y}{r^2} & \dfrac{p_x}{r^2} & 0 & 0 \end{bmatrix} $$
El ile türetilen bir Jacobian, hata yapmaya en açık yerdir; bu yüzden onu daima sayısal türevle doğrulayın. (h(x+ε) − h(x−ε)) / 2ε merkezî farkı, analitik Jacobian’a çok yakın çıkmalıdır:
import numpy as np
def h(x): return np.array([np.hypot(x[0], x[1]), np.arctan2(x[1], x[0])])
def H_jac(x):
px, py = x[0], x[1]; r2 = px*px + py*py; r = np.sqrt(r2)
return np.array([[ px/r, py/r, 0, 0],
[-py/r2, px/r2, 0, 0]])
x = np.array([3.0, 4.0, 1.0, -2.0]) # r = 5
eps = 1e-6; J_num = np.zeros((2, 4))
for i in range(4):
e = np.zeros(4); e[i] = eps
J_num[:, i] = (h(x+e) - h(x-e)) / (2*eps)
print(np.max(np.abs(H_jac(x) - J_num))) # -> ~7e-9 (analitik = sayısal)
print(H_jac(x)) # [[ 0.6 , 0.8 , 0, 0], [-0.16, 0.12, 0, 0]]
Maksimum fark ~10⁻⁹ mertebesinde; Jacobian’ımız doğru. (p_x=3, p_y=4 için r=5; 3/5=0.6, 4/5=0.8, −4/25=−0.16, 3/25=0.12 — elle de doğrulayabilirsiniz.)
EKF Algoritması
EKF döngüsü, klasik KF’ten yalnızca iki yerde ayrılır. Önce ölçüm modelimizin sabit F matrisini (bu örnekte hareket doğrusal: 2B sabit hız) ve Q‘yu kuralım:
$$ F = \begin{bmatrix} 1&0&\Delta t&0 \\ 0&1&0&\Delta t \\ 0&0&1&0 \\ 0&0&0&1 \end{bmatrix}, \qquad Q = G\,\sigma_a^2\,G^{\mathsf{T}},\quad G = \begin{bmatrix} \tfrac{\Delta t^2}{2}&0 \[2pt] 0&\tfrac{\Delta t^2}{2} \[2pt] \Delta t&0 \[2pt] 0&\Delta t \end{bmatrix} $$
EKF adımları:
$$ \hat{x}_k^- = f(\hat{x}_{k-1}, u_{k-1}), \qquad P_k^- = F_k\,P_{k-1}\,F_k^{\mathsf{T}} + Q $$
$$ y_k = z_k - h(\hat{x}_k^-), \qquad S_k = H_k\,P_k^-\,H_k^{\mathsf{T}} + R $$
$$ K_k = P_k^-\,H_k^{\mathsf{T}}\,S_k^{-1}, \quad \hat{x}_k = \hat{x}_k^- + K_k\,y_k, \quad P_k = (I - K_k H_k)\,P_k^- $$
İki kritik fark:
-
Ortalama gerçek fonksiyonla, kovaryans Jacobian’la taşınır. Yeniliği
z − H x̂⁻değil,z − h(x̂⁻)ile hesaplarız; amaS,K,PdenklemlerindeHyerineH_kJacobian’ı kullanırız. -
Açı farkını sarmak (wrapping).
atan2değerleri[−π, π]aralığındadır.179°beklerken−179°ölçerseniz, ham fark−358°çıkar; oysa gerçek fark sadece+2°‘dir. Bu yüzden açı yeniliğini daima[−π, π]aralığına sararız:
$$ y_\theta \leftarrow \big((y_\theta + \pi)\bmod 2\pi\big) - \pi $$
Bu küçük detayı atlamak, takip sistemlerinin açı sıçramalarında neden aniden çıldırdığının bir numaralı sebebidir. Aşağıdaki diyagram iki filtrenin yapısal farkını özetliyor:
(doğrusal)"] K2["Ölçüm: z = H·x
(doğrusal)"] K3["Kovaryans: F ve H
sabit matrisler"] K1 --> K2 --> K3 end subgraph EKF["Genişletilmiş KF (EKF)"] direction TB E1["Model: x = f(x, u)
(doğrusal-olmayabilir)"] E2["Ölçüm: z = h(x)
(doğrusal-olmayan)"] E3["Kovaryans: her adımda
Jacobian Fₖ = ∂f/∂x , Hₖ = ∂h/∂x"] E1 --> E2 --> E3 end KF -. "aynı 2 adımlı döngü;
tek fark: lineerizasyon" .-> EKF style KF fill:#e8f0fb,stroke:#3a5f95,stroke-width:2px style EKF fill:#fbf0e8,stroke:#a05a2c,stroke-width:2px style K3 fill:#cee0f3,stroke:#3a5f95 style E3 fill:#f5dcc3,stroke:#a05a2c
NumPy ile Sıfırdan EKF: Range-Bearing Takibi
Hepsini bir araya getirelim. Aşağıdaki kod, sabit hızla giden (ama yavaşça dönen) bir hedefi, orijindeki menzil-açı sensörüyle takip eder. Klasik KF kodumuzdan tek farkı, h fonksiyonu, H_jac Jacobian’ı ve açı sarması.
import numpy as np
dt = 1.0
F = np.array([[1,0,dt,0],[0,1,0,dt],[0,0,1,0],[0,0,0,1.0]]) # 2B sabit hız
G = np.array([[dt**2/2,0],[0,dt**2/2],[dt,0],[0,dt]])
Q = G @ (0.02*np.eye(2)) @ G.T
sr, sth = 0.5, np.deg2rad(1.0) # menzil (m) ve açı (rad) gürültüsü
R = np.diag([sr**2, sth**2])
def h(x): # doğrusal-olmayan ölçüm
return np.array([np.hypot(x[0], x[1]), np.arctan2(x[1], x[0])])
def H_jac(x): # ölçüm Jacobian'ı (2x4)
px, py = x[0], x[1]
r2 = px*px + py*py; r = np.sqrt(r2)
return np.array([[ px/r, py/r, 0, 0],
[-py/r2, px/r2, 0, 0]])
def wrap(a): # açıyı [-π, π] aralığına sar
return (a + np.pi) % (2*np.pi) - np.pi
# Gerçek hedef: sabit hız + yavaş dönüş; sensör orijinde
rng = np.random.default_rng(4)
N = 55
xt = np.array([-26.0, 9.0, 1.4, 0.25])
c, s = np.cos(np.deg2rad(2.2)), np.sin(np.deg2rad(2.2))
truth, meas = [], []
for _ in range(N):
truth.append(xt.copy())
meas.append(h(xt) + np.array([rng.normal(0, sr), rng.normal(0, sth)]))
xt = F @ xt
xt[2:] = np.array([[c, -s], [s, c]]) @ xt[2:] # hız vektörünü döndür
truth, meas = np.array(truth), np.array(meas)
# EKF döngüsü
xhat = np.array([-24.0, 12.0, 0.0, 0.0])
P = np.diag([16., 16., 9., 9.])
I = np.eye(4); est = []
for k in range(N):
# --- TAHMİN (f doğrusal → F sabit) ---
xhat = F @ xhat
P = F @ P @ F.T + Q
# --- GÜNCELLEME (h doğrusal-olmayan → Jacobian) ---
Hk = H_jac(xhat)
y = meas[k] - h(xhat); y[1] = wrap(y[1]) # açı farkını sar!
S = Hk @ P @ Hk.T + R
K = P @ Hk.T @ np.linalg.inv(S)
xhat = xhat + K @ y
P = (I - K @ Hk) @ P
est.append(xhat.copy())
est = np.array(est)
rmse = np.sqrt(np.mean(np.sum((est[:, :2] - truth[:, :2])**2, axis=1)))
print(f"EKF konum RMSE = {rmse:.2f} m") # -> 0.56 m
Burada hareketin doğrusal olduğuna (f = sabit F) ama ölçümün doğrusal-olmadığına dikkat edin: tüm doğrusal-olmama h ve H_k‘de yaşıyor. Her adımda yeniden hesaplanan tek şey Hk Jacobian’ı. Sonuç: 1°’lik açı ve 0.5 m’lik menzil gürültüsüne rağmen konum RMSE’si 0.56 m — sensörün ham gürültüsünün epey altında.
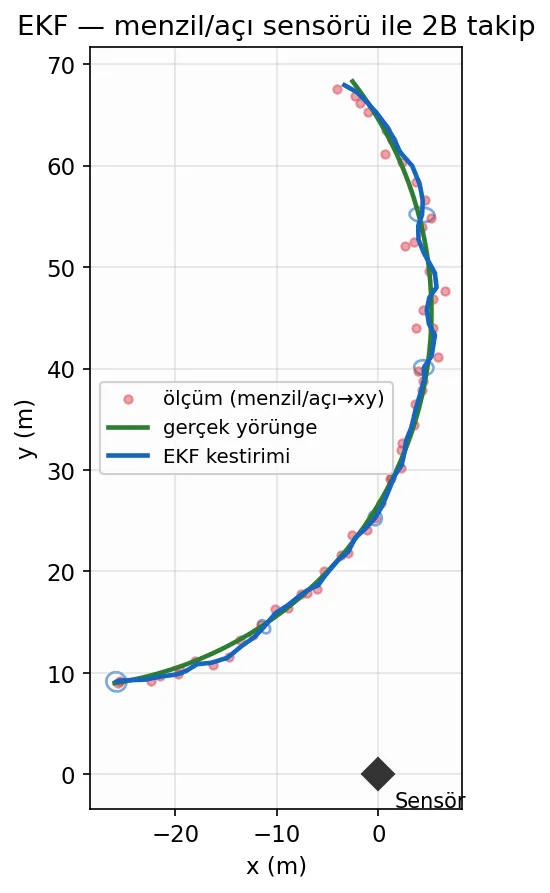
Etkileşimli Simülatör: Genişletilmiş Kalman Filtresi
Şimdi EKF’i canlı izleyelim. Bu sefer üstten bakışlı 2B bir görünüm var: orijinde sensör, dönen bir hedef ve EKF’in kovaryans elipsi. Menzil ve açı gürültüsünü, filtrenin süreç gürültüsünü ve hedefin dönüş hızını ayarlayabilirsiniz.
Sensör orijinde. Hedef uzaktayken 2σ elipsi açı (teğet) yönünde şişer — uzakta küçük bir açı hatası büyük yanal hataya dönüşür. Hedef sensöre yaklaştıkça elips daralır: gözlemlenebilirliğin (observability) görünür hâli.
En öğretici deney: açı gürültüsünü (σ_θ) büyütün ve kovaryans elipsinin nasıl bir muz şeklini aldığını izleyin. Elips, sensöre olan doğrultuya dik (teğetsel) yönde uzar; çünkü uzak bir hedefte 1°’lik açı hatası, metrelerce yanal konum hatası demektir — oysa menzil yönündeki belirsizlik küçük kalır. Dönüş hızını artırırsanız, sabit-hız varsayan filtrenin manevra anlarında gerçek yörüngenin dışına savrularak geciktiğini görürsünüz; bu, model uyumsuzluğunun (model mismatch) doğrudan görsel kanıtıdır.
Mühendislik Notları: Q, R Ayarı, Iraksama ve Sayısal Kararlılık
Filtreyi çalıştırmak kolay; doğru çalıştırmak ustalık ister. Sahaya çıkmadan önce kontrol listesi:
-
Asıl mesele
Q/Roranıdır.Rçoğu zaman sensörün veri sayfasından ya da statik kalibrasyondan bilinir; gerçek ayar düğmesiQ‘dur. Mutlak değerlerden çok,QileRarasındaki oran filtrenin karakterini belirler: büyükQ/R→ çevik ama gürültülü; küçükQ/R→ pürüzsüz ama tembel ve manevrada geciken. Simülatörlerde bunu elinizle hissettiniz. -
Filtrenin tutarlılığını ölçün (NIS/NEES). Filtre yalnızca doğru tahmin etmemeli, belirsizliği hakkında da dürüst olmalı. Yenilik
yile kovaryansıSkullanılarak hesaplanan normalize yenilik karesi (NIS), istatistiksel olarak bir χ² dağılımına uymalıdır. YeniliklerS‘in öngördüğünden sürekli büyükse filtre fazla iyimserdir (QveyaRküçük); sürekli küçükse fazla karamsardır. NIS, “filtrem yalan söylüyor mu?” sorusunun nicel cevabıdır. -
Iraksamaya (divergence) karşı uyanık olun. En sinsi hata,
P‘nin gerçek hatadan çok daha küçük olması — filtre kendine güvenir, gelen ölçümleri “aykırı” sanıp reddeder, gerçekten gitgide kopar. Sebepleri: çok küçükQ, modellenmemiş bir dinamik, ya da sayısal yuvarlama. Lineer simülatördeq‘yu dibe çekerek bunu birebir görebilirsiniz. -
Sayısal kararlılık için Joseph formunu kullanın.
P = (I − KH)P⁻denklemi, kayan-nokta yuvarlamasıylaP‘yi asimetrik veya negatif-tanımlı yapabilir; bu da filtreyi çökertir. Joseph formuP = (I−KH)P⁻(I−KH)ᵀ + KRKᵀher zaman simetrik ve pozitif yarı-tanımlı sonuç verir. Ek maliyet birkaç matris çarpımıdır; gömülü sistemlerde ucuz bir sigortadır. Her adımdaP‘yi(P + Pᵀ)/2ile simetrikleştirmek de yaygın, ucuz bir önlemdir. (Kayan-nokta tuzakları üzerine ayrı bir yazı yazmıştım; Kalman filtresi bu tuzakların en çok ısırdığı yerlerden biridir.) -
Gözlemlenebilirliği (observability) sorgulayın. Yalnızca menzil ölçen bir sensör, hedefin açısal konumunu tek başına belirleyemez; takip ancak hedef hareket ettikçe ve geometri değiştikçe oturur. EKF simülatöründe elipsin yöne bağlı şişmesi tam da bunun resmidir. Durumunuzun ölçümlerinizden gerçekten çıkarılabilir olduğundan emin olun.
-
EKF’e özgü tehlike: lineerizasyon hatası. Başlangıç tahmini gerçekten uzaksa ya da fonksiyon çok bükülmüşse, teğet kötü bir yaklaşım olur ve EKF ıraksar. Çok keskin doğrusal-olmamalıkta, türev almayan Unscented Kalman Filtresi (UKF) — dağılımı seçili “sigma noktalarıyla” temsil eder — genellikle daha sağlamdır ve Jacobian türetme derdini ortadan kaldırır. Dağılım çok-modlu (multimodal) veya gürültü Gauss’tan çok uzaksa, sıra parçacık filtresine (particle filter) gelir: dağılımı binlerce örnekle temsil eden, hesapça pahalı ama çok genel bir yöntem.
Sonuç
Kalman filtresi, ilk bakışta matris denklemlerinden oluşan korkutucu bir reçete gibi görünür. Oysa altında yatan fikir tek bir cümleyle özetlenir: iki Gauss bilgiyi — modelin tahmini ile sensörün ölçümünü — her birinin belirsizliğine göre tartarak birleştir, sonra tekrarla. Tahmin adımı belirsizliği büyütür, güncelleme adımı küçültür; bu nefes alıp verme sonsuza dek sürer.
EKF ise aynı makinenin doğrusal-olmayan dünyaya uzanmış hâlidir: her adımda fonksiyonları çalışma noktasında bir teğetle değiştirir, gerisini değiştirmez. Bu küçük numara, onu yarım asırdır navigasyondan robotiğe kadar her yerde çalışan bir iş atı yapmıştır — kusursuz değil, ama şaşırtıcı derecede dayanıklı.
Tasarımınızın kaderini üç şey belirler: modelin (F, H ya da f, h) gerçeğe sadakati, Q‘nun ve R‘nin doğru ayarı. Bu üçünü yerine oturtursanız, gürültünün altından şaşırtıcı netlikte bir gerçek çıkarırsınız. Yanlış ayarlarsanız, filtre ya tembelce gerçeğin peşinden sürüklenir ya da kendine aşırı güvenip sessizce ıraksar. Her iki sonu da sahada görmek mümkün — ve artık ikisini de tanıyorsunuz.
Devamı için iyi konular: durum boyutu büyüdüğünde kare-kök (square-root) filtreleri sayısal kararlılığı nasıl kurtarır; UKF sigma noktalarıyla Jacobian’a neden hiç ihtiyaç duymaz; ve birden çok hareket modelini paralel koşturan IMM (Interacting Multiple Model) manevra yapan hedeflerde neden EKF’i döver. Bunlar defterimde duruyor.
Kaynaklar:
- R. E. Kálmán — “A New Approach to Linear Filtering and Prediction Problems”, Journal of Basic Engineering, Vol. 82, No. 1, 1960, pp. 35–45. (Her şeyin başladığı makale.)
- Greg Welch, Gary Bishop — An Introduction to the Kalman Filter, UNC-Chapel Hill, TR 95-041. (Klasik, sade giriş.)
- Sebastian Thrun, Wolfram Burgard, Dieter Fox — Probabilistic Robotics (MIT Press, 2005), Bölüm 3: “Gaussian Filters”. (KF ve EKF’in olasılıksal türetimi.)
- Dan Simon — Optimal State Estimation: Kalman, H∞, and Nonlinear Approaches (Wiley, 2006). (Joseph formu, kare-kök filtreleri ve sayısal konular için referans.)
- Yaakov Bar-Shalom, X.-Rong Li, Thiagalingam Kirubarajan — Estimation with Applications to Tracking and Navigation (Wiley, 2001). (Menzil-açı takibi, NIS/NEES tutarlılık testleri.)
- S. J. Julier, J. K. Uhlmann — “Unscented Filtering and Nonlinear Estimation”, Proceedings of the IEEE, Vol. 92, No. 3, 2004. (EKF’in ötesi: UKF.)
- Roger Labbe — Kalman and Bayesian Filters in Python. (Etkileşimli, kod-ağırlıklı ücretsiz kitap.)